C++: Dynamically Allocating Memory
Usually when declaring variables using C++, the compiler "tells" the executable file that it creates how much memory is going to be needed to run the program. This memory can then be allocated before the program is run to provide the appropriate space. This is great for the most part as it usually means that most of your data is stored in a similar location, and more importantly it means that you have a big chunk of memory which the compiler manages for you. We haven't had to really worry about variables we've created - we don't have to worry about deleting memory which we've allocated or anything like that, the compiler does it all for us.
You can, however, allocate memory dynamically in C++. Dynamic memory allocation is the allocation and ownership of memory for a certain data structure at runtime (while your program is running, hence dynamically), and this makes flexible data sizes and dynamic object creation possible (and easy!). When you dynamically allocate memory you're essentially saying "Hey! Give me my own chunk of memory over here!" -- you can really do whatever you want with this memory however you're responsible for clearing up (and freeing) the memory when you've finished using it. The topic of dynamic memory allocation behind the scenes is somewhat complex, but in this tutorial we're just going to go over the basics of allocating and using memory "on the fly" using C++, and more specifically, using the new keyword.
Perhaps the simplest example of dynamic memory allocation would be to declare and initialize an integer variable dynamically. Dynamic memory isn't accessed like "normal variables", but is instead utilized through pointers - this is one of the reasons why pointers are such an extremely powerful force in C++. The basic idea is that we create a new pointer, and then point this to a "new" block of memory which we've allocated, and then we can simply use the pointer to write to that memory. This is all done, of course, around the data-type of whatever we want to store. So to follow our concept with an example, a new integer pointer would be declared, and then we would make this point to a new section of memory of size sizeof(int) (which, on most machines, is four bytes).
This new section of memory which we keep talking about, can be allocated by using the new keyword, followed by the data-type (whether a core data-type like an integer, or something more abstract like a custom struct or class). The general process of declaring a new pointer, setting it to a newly (and dynamically) allocated section of memory, and then setting the value at that location, is shown in the diagram below:
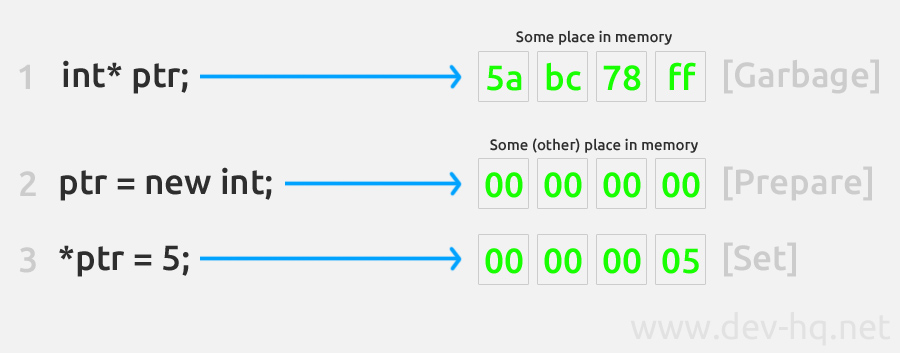
As alluded to in the diagram above, once the pointer is set to a new section of memory we can simply treat it like a normal integer pointer - using the dereference operator (*) to set the value at the memory location. This means we can essentially treat it just like an integer variable if we just use the dereference operator. As I mentioned earlier, however, we do need to clean up after ourselves. If we've allocated four bytes (or whatever sizeof(int) is) of memory, we need to "delete" this or free it up when we're finished with it or it will just hang around in memory, creating what is known as a memory leak. This is done, in this case, by writing the delete keyword followed by the pointer name - so delete ptr;:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
The only problem with our examples so far is that, to be frank, they aren't all that useful. Our programs are performing tasks which they could just as easily perform using "normal" variables, and the only real differences are behind the scenes.
One of the key use-cases for dynamically allocating memory is when you don't know how much memory you'll need to allocate. Say, for example, we had a program which took in the number of students in a class and then created an array with this size. We cannot, using "normal" techniques, create an array with a flexible size like this, but using dynamically allocated memory, such a task could be done with relative ease. We can simply take in the size (straight into an integer variable using cin if we don't want to worry about string-to-int conversion), and then create a new integer pointer which points to the start of a new integer array. Since arrays are essentially just pointers to the first element of the array, we can simply do this with int* array = new int[size];.
From here, we can simply treat the integer pointer like an array - we don't even need to use the dereference operator because the square brackets handle all of that for us, arrays just being pointers and all. We can then proceed to do whatever the hell we want with the array, and then free up the memory by using the delete keyword, followed by some empty square brackets to indicate that we're dealing with an array, followed by the pointer (or "array" if you like) name. This is shown in the code snippet as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
We could, of course, make use of manual pointer arithmetic here if we wanted to use this instead of using the square bracket notation - but square brackets seem to make more sense in this instance. It's worth noting that if we wanted to, we could actually set the 'array' pointer to another new section of memory to create a different array after we deleted the old one - this technique is utilized in the creation of many applications.
Another common use for dynamic memory allocation is creating objects and other data structures only where it is necessary. Let's say, for example, we had a really big custom struct that required a bunch of data - perhaps some kind of video data or something. If we just declared the object normally with something like ReallyBigStruct object; in our code, the space for this object would be allocated in preparation for our program to run. If we allocate the memory dynamically however, the memory will only be allocated once we use the new keyword. Take for example the following example in which we might not want to create the object "regularly" as we are:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
The above would be extremely memory inefficient in cases in which 'option' was false, and as such, it would probably be a good idea to dynamically allocate the memory for the ReallyBigStruct object. This can be done by simply using the new keyword just like we did with the ints at the start of this tutorial - we can simply create a pointer to whatever data-type we want to allocate/store dynamically, and then use the new keyword:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
The above is much more memory efficient. Note that instead of using new and delete, we could make use of the malloc and free C functions which are being used behind the scenes. It can be dangerous to use these, however, as they don't always behave as expected, and as such I'd recommend staying with new and delete wherever possible (also, new and delete are really the C++ way of doing things).
We should also quickly talk about dynamic memory allocation in classes. There are a number of different approaches to designing classes which make use of dynamic memory allocation - the traditional approach is where the programmer must clean up after the object, calling .close() methods and the like to clear any memory which class objects have allocated, however this can lead to a number of problems, namely that the programmer can easily make a mistake and that if something goes horrible wrong before these vital memory clearing function calls, a memory leak will occur. As such, the RAII programming idiom is becoming increasingly popular for C++ class design.
RAII stands for Resource Acquisition Is Initialization, and the basic idea is that a class's constructor should deal with dynamic allocation of memory, and that a class's destructor should deal with the de-allocation of allocated memory. This way, the memory is always de-allocated when the object is destroyed, and thus memory leaks are prevented even in exceptional circumstances. This can cause a number of complexities to class design depending on the complexity of the class, but if done right can lead to very good practices for allocating and de-allocating memory in which the programmer doesn't have to worry quite as much about memory leaks from dynamic memory allocation from class objects, as objects really manage their own memory.